
 Qualitätsbetriebe.com
Qualitätsbetriebe.com Bauherrenhilfe.tv
Bauherrenhilfe.tv








PDF_Mit welcher KI soll ich nun sprechen?
Bereits im ersten Beitrag wurde die derzeit bekannteste Künstliche Intelligenz „ChatGPT“ von OpenAI erwähnt. Laut der neuen KI-Verordnung (AI-Act) handelt es sich dabei um sogenannte KI-Modelle mit allgemeinem Verwendungszweck (General Purpose AI Models, kurz: GPAI-Models). Diese Modelle werden nicht für eine spezifische Aufgabe entwickelt und können daher flexibel für zahlreiche Anwendungen in der Verarbeitung und Generierung unstrukturierter Texte, Bilder, Audios und Videos eingesetzt werden. In einem der vorherigen Beiträge wurde die Unterscheidung von KI in „starke“ KI (auf einer Ebene mit dem Menschen) und „schwache“ KI (nur für eine spezifische Aufgabe ausgelegt) erläutert. GPAI-Modelle bewegen sich zwischen diesen Kategorien, werden jedoch eher als fortschrittliche „schwache“ KI betrachtet. Mit welchen GPAI-Modellen haben wir es also zu tun und wie funktionieren diese?
Hinter dem uns bekannten Chatbot „ChatGPT“ von OpenAI steckt ein komplexes „Transformer-Modell“, das zu den GPAI-Modellen (laut AI Act) gezählt werden kann und übergeordnet als „Large Language Model“ (LLM, „großes Sprachmodell“) bezeichnet wird. Diese Transformer basieren auf fortschrittlichen neuronalen Netzwerken, die in den nächsten Beiträgen näher betrachtet werden. Die Sprachmodelle hinter ChatGPT heißen beispielsweise GPT-4 oder GPT-4o (veraltet ist GPT-3.5). GPT steht für „Generative Pre-trained Transformer“. Kurz gesagt: Das Modell wurde vorher mit großen Datensätzen trainiert und kann bei einer neuen Eingabe die Beziehungen zwischen Wörtern in einem Satz erkennen, um so einen passenden Output zu generieren. Der Begriff ChatGPT bezeichnet „nur“ die Benutzeroberfläche bzw. die Chatbot-App, über die Menschen mit dem Sprachmodell interagieren können. Mittlerweile sind die typischen Sprachmodelle nicht mehr nur Sprachmodelle, sondern vielmehr „multimodale“ Modelle. Neben der Fähigkeit, Sprache bzw. Texte zu verarbeiten, verfügen sie auch über weitere „Modi“ wie die Audio- und Bildverarbeitung. Sprache in Form von Texten war in den veralteten Modellen wie GPT-3.5 der einzige „(Daten-)Modus“.
Die Modelle von OpenAI (z. B. GPT-4) sind jedoch nicht die einzigen großen KI-Modelle. Beispielsweise gibt es auch KI-Modelle von Meta AI (Llama 3.1-405B), Mistral AI
(Mistral Large 2), Google DeepMind (Gemini 1.0 Ultra) oder Anthropic (Claude 2). Diese
KI-Modelle sind jeweils im Hintergrund einer eigenen Benutzeroberfläche implementiert. Die Benutzeroberfläche (die Chatbot-App) für Mistral Large 2 heißt „le Chat“. Die Unterscheidung zwischen dem KI-Modell (z. B. GPT-4 oder Mistral Large 2) und der Benutzer-App (z. B. ChatGPT oder le Chat) ist wichtig, da die KI-Modelle für die Anwendungen im eigenen Unternehmen von Bedeutung sind. Der Chatbot „Microsoft Copilot“ nutzt beispielhaft ebenfalls das Sprachmodell GPT-4. Es ist wichtig, die Eigenschaften dieser unterschiedlichen Modelle zu erkennen, da sie sich rasant weiterentwickeln (nicht zu vergessen ist der Datenschutz).
Nach welchen Parametern kann eine Unterscheidung der KI-Modelle vorgenommen werden? Die Komplexität und Leistungsfähigkeit eines Modells kann beispielsweise anhand der Rechenoperationen beurteilt werden, die während des Trainings erforderlich waren. Diese Kennzahl wird als Gesamt-FLOPs (FLoating Point OPerations, auf Deutsch: Gleitkommaoperationen) bezeichnet. Sie gibt an, wie oft im Rahmen einer Berechnung Operationen wie Addition, Subtraktion, Multiplikation oder Division durchgeführt werden (z. B. enthält der Ausdruck zwei FLOPs, da zuerst multipliziert und dann addiert wird). Der AI-Act bezieht sich dabei auf die kumulative Gesamtrechenleistung während des Trainings über einen längeren Zeitraum z. B. Monate (FLOPs) und nicht auf die Rechenleistung pro Sekunde (FLOPS, FLoating Point OPerations Per Second). Die nachfolgende Abbildung 1 zeigt die Gesamtrechenoperationen für verschiedene
KI-Modelle weltweit.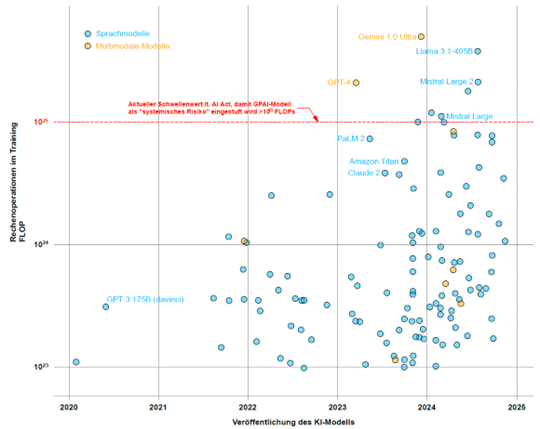
Abbildung 1: Darstellung verschieden großer KI-Modelle und ihre Gesamtrechenoperationen für das KI-Training (Quelle: https://epoch.ai/data/large-scale-ai-models, 02.12.2024)
Nur ein Bruchteil der vorhandenen KI-Modelle ist beschriftet und lediglich einige davon haben die definierte Schwelle von mehr als Gesamtrechenoperationen gemäß dem AI-Act überschritten. Ab dieser Schwelle sind zusätzliche gesetzliche Verpflichtungen zu beachten. Inwieweit dieser Schwellenwert aus aktueller Perspektive begründet ist, lässt sich nicht eindeutig sagen. Es ist jedoch davon auszugehen, dass hier künftig immer wieder Anpassungen erforderlich sein werden. Hervorzuheben ist außerdem, dass Mistral das einzige große KI-Modell aus Europa (Frankreich) ist, während die meisten anderen Modelle aus den USA stammen. Aus aktueller Sicht ist die Informationslage rund um diese KI-Modelle sehr unübersichtlich, da viele Parameter (wie Rechenleistung, Datenmenge oder allgemeine Lernparameter) oft nur geschätzt werden können und nicht direkt von den Entwicklern veröffentlicht werden. Diese Vergleiche sollten daher stets mit Vorsicht betrachtet werden. Aufgrund der rasanten und konkurrierenden Entwicklung ist es ohnehin schwierig, das „richtige“ Modell für eine Anwendung in den Unternehmensprozessen auszuwählen. Weitere Informationen hierzu folgen.

Markus Nussbaum, Bauingenieur & KI-Beauftragter, in Kooperation mit tecTrain.at ![]()
(Veröffentlicht am 16.12.2024)